From Volumetric Pipelines to Neural Chains: Why My Work in 3D Media Over 5G Built the Blueprint for Monmouth
In the early 2020s, I was leading volumetric compression pipelines at Verizon—taking multi-terabyte-per-minute 3D video streams and optimizing them for delivery over 5G networks.
From Volumetric Pipelines to Neural Chains: Why My Work in 3D Media Over 5G Built the Blueprint for Monmouth
In the early 2020s, I was leading volumetric compression pipelines at Verizon—taking multi-terabyte-per-minute 3D video streams and optimizing them for delivery over 5G networks. At the time, we were solving problems most people didn’t know existed yet: how to capture, compress, and transmit real-time, photorealistic 3D humans and environments so convincingly that a doctor could diagnose a patient across the country using nothing more than a headset.
What I didn’t realize then was that this work—handling massive edge-side datasets, architecting ultra-low-latency systems, and designing real-time workflows between client and edge—was a blueprint for something much bigger. It wasn’t just media engineering. It was an early sketch of what a neural blockchain would need to look like.
Today, that sketch has become Monmouth.
The Volumetric Era: Edge-Latency as a First Principle
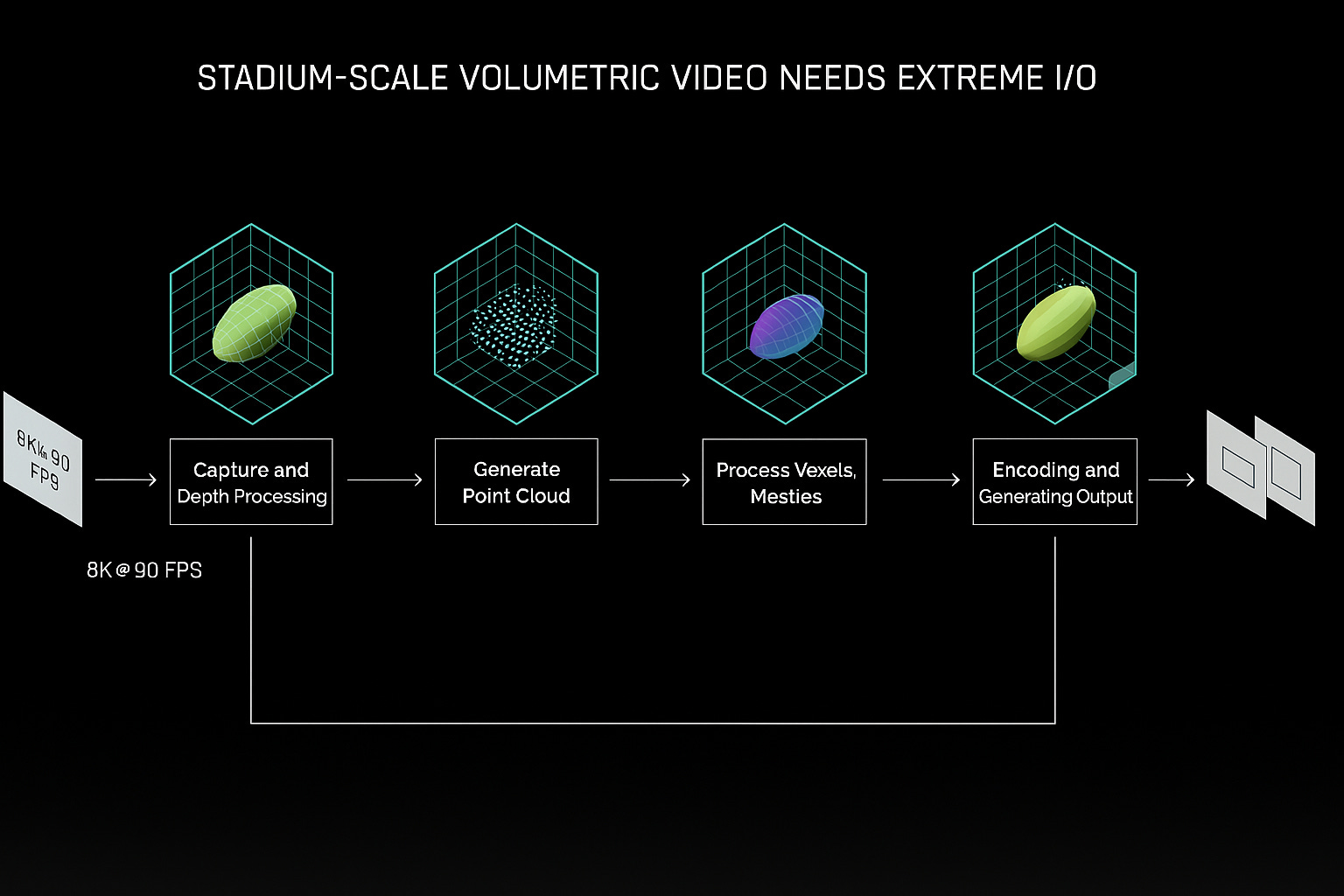
Volumetric capture isn’t just about cool visuals. It’s a systems-level challenge:
150+ 4K cameras generating terabytes per minute
Real-time stitching, meshing, and rendering
Hybrid compute between edge nodes and GPU clients
60/90/120Hz feedback loops that must never break
At Verizon, we couldn’t afford latency drift. Inputs traveled from device to edge within 10ms. Frame updates were computed, encoded, and sent back without ever breaking the input loop. Custom codecs, hybrid offloading, spatial compression, structured light depth imaging, and pointcloud pruning weren’t “nice to have”—they were required for the experience to even function.
It was during this time that I developed my intuition for latency as a constraint, not a goal. And it’s that same principle that underpins Monmouth’s sub-250ms block finality and real-time agent infrastructure.
Volumetric Architectures as a Precursor to Agent Systems
Volumetric media wasn’t just about humans-as-data. It taught us how to treat dynamic scenes as first-class data citizens—representing time, space, and motion as composable primitives.
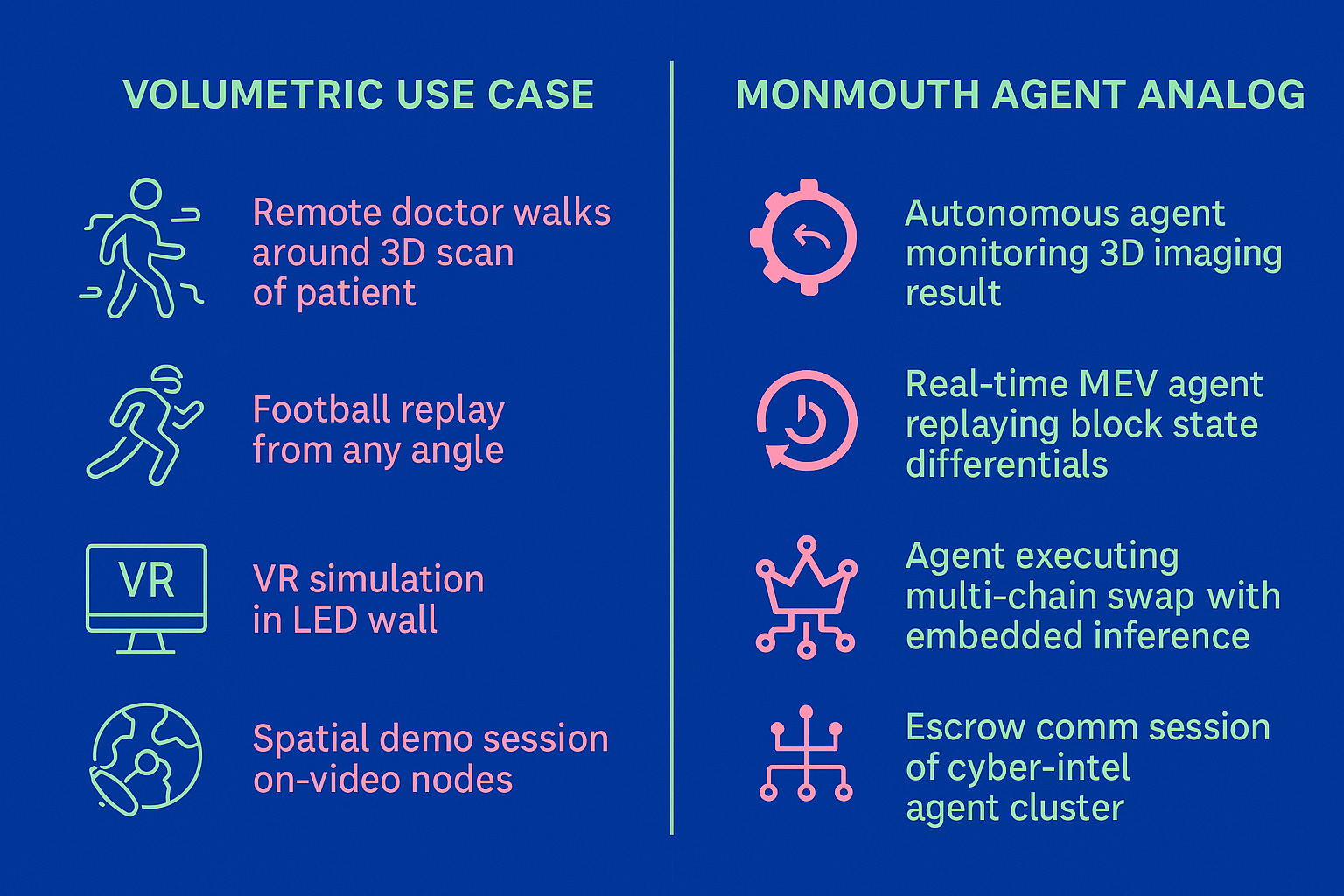
Now, zoom out. Replace:
3D players → with AI agents
volumetric meshes → with on-chain state diffs
pointcloud compression → with ExEx-triggered memory snapshots
edge-side scene reactivity → with node-native agent inferences
Suddenly, the volumetric stack becomes a prototype for on-chain agent ecosystems:
Short-term memory = ephemeral pointclouds
Long-term memory = compressed agent embeddings
Context-aware frame interpolation = RAG-enhanced inference chains
Real-time spatial streaming = ExEx post-execution hooks
The memory-first, latency-conscious systems we built for immersive 3D are structurally identical to what AI-native chains now require.
Monmouth: A Chain Born from Low-Latency Media
Monmouth isn’t built like traditional chains. It’s not just “faster EVM.” It’s a neural infrastructure layer—engineered for real-time agent transactions, vector-aware state, and dynamic context windows that adapt on the fly.
Where others chase throughput, we chase responsiveness.
And where most chains treat agents as off-chain afterthoughts, we treat them as on-chain primitives. We embed RAG pipelines, run vector databases in-memory, and use Execution Extensions (ExEx) to trigger inference within the node lifecycle—just like we used to trigger encoder updates within a 10ms window at the Verizon edge.
This architecture wasn’t inspired by crypto. It was forged in the crucible of real-world systems where feedback loops can’t break, where latency isn’t negotiable, and where experience is only possible if the pipeline is smarter than the data it's handling.
Use Cases We Understood Before Crypto Did
Here’s where it comes full circle:
When I see the current hype around “AI x Crypto,” I see surface-level integrations. LLMs calling JSON-RPC. Agents prompting other agents. Bridges riddled with friction and latency.
What Monmouth offers instead is a neural substrate, not an AI add-on.
The New Frontier: From Terabytes per Minute to Milliseconds per Block
The volumetric pipelines I built at Verizon taught me how to manage terabytes of data in real time. The systems didn’t tolerate delay, and neither does Monmouth.
Now we’re applying those lessons to a new domain:
High-memory nodes replace GPU edge boxes
ExEx hooks replace scene encoders
Vector databases replace spatial indexing
AI agents replace actors on a LED wall
And just like before, the key to it all is coherence + context.
Final Thoughts: You Can’t Fake Latency
In crypto, everyone talks throughput. TPS. Compression. But here’s what they don’t talk about: latency you can feel.
At Verizon, latency wasn’t a line in a whitepaper. It was the difference between a seamless frame and a user vomiting in an AR headset. We didn’t have the luxury of “eventual consistency.” We had to be consistent right now.
That’s the world I come from.
And that’s why I built Monmouth.
TL;DR
If you want to understand why Monmouth is different, don’t just look at the code. Look at where I’ve been. The neural stack I’m building wasn’t born in a crypto Discord. It was born in the data centers and edge clusters of the biggest telecom in the world—where latency wasn’t optional, and every frame counted.
Now imagine that same rigor applied to chain design.
That’s Monmouth.